もはや多くの生成AIに備わっている「検索」の機能。
この検索機能を用いたウェブでの調査能力を調べた結果がこの度公表されました。
その結果、多くのモデルで調査能力が大きく向上していることが判明!
一体どういうことなのか、見ていきましょう。
今回調査を行ったのは、FutureSearch社というカリフォルニア州サンブルーノに本拠を置く調査会社。
どういう調査を行ったかというと、現実世界の「雑多な」ウェブ調査タスクを89件設定し、11種類の主要LLMエージェントに実行させて比較評価する、というものです。
評価指標は、「完璧な人間の研究者」を1.0ではなく0.8と仮定した上でのスコアとしており、各AIエージェントのスコアを0–1のレンジで評価しました。
つまり、スコアの値が0.8に近づけば近づくほど、優秀な人間に近い調査能力を持つということです。
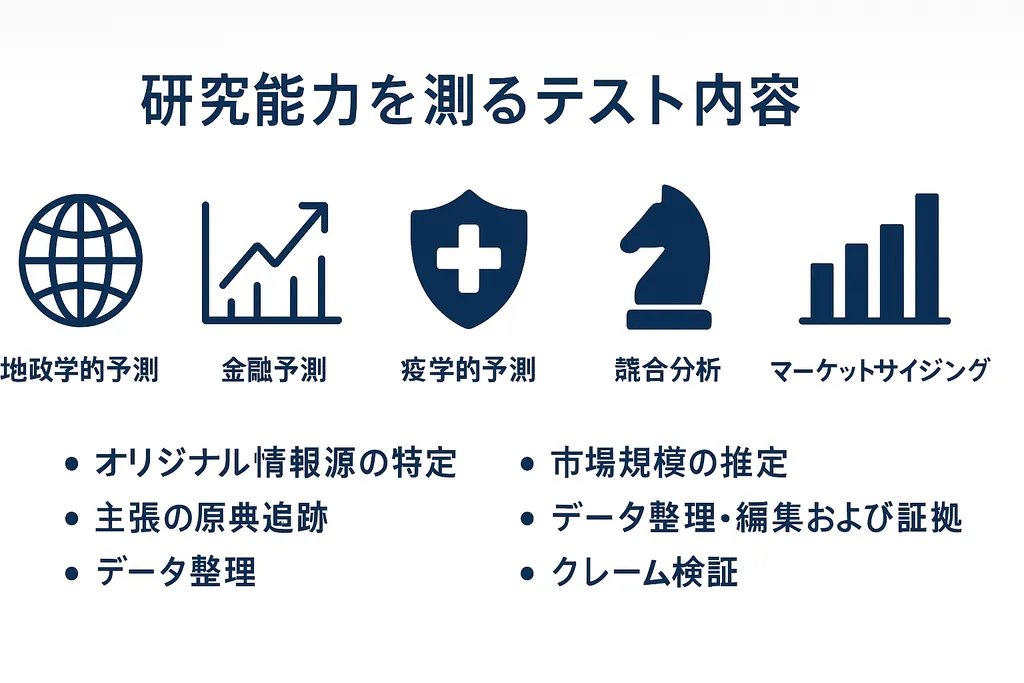
ちなみに、調査能力を測るテスト内容は、
- 地政学的予測
- 金融予測
- 疫学的予測
- 競合分析
- マーケットサイジング
などの分野の調査を行わせて、具体的には
- オリジナル情報源の特定
- 市場規模の推定
- 主張の原典追跡
- データ整理・編集および証拠収集
- クレーム検証
などというタスクをさせたということです。
調査結果は…
それぞれのAIの調査能力を測った結果、次のようになりました。
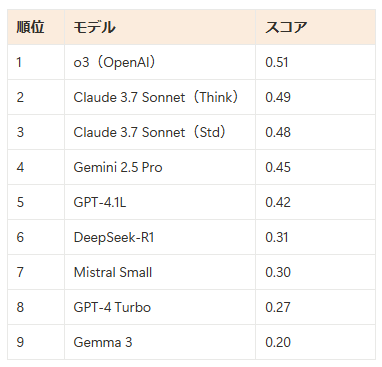
OpenAIの最新モデルであるo3がやはり一番高いスコアを獲得し、0.51となりました。
「優秀な人間研究者」(0.8)には及ばないものの、1年前のモデル(GPT-4 Turbo)のスコア(0.27)に比べると、わずか1年で0.51まで約45%も改善したことが分かります。
AIの進化スピードが非常に速いことが分かりますね。1年後には優秀な人間と同等のスコアを獲得するのも夢ではありません。
さて、なぜo3はスコアが高かったのでしょうか。
これには**サティスファイシング(妥協行動)**というのが影響していると言われています。
サティスファイシングは最適解(maximizing)ではなく、「一定水準以上の満足を得られる解」を目指して探索を打ち切る意思決定戦略のことをいうのですが、経済学、心理学、行動経済学などで幅広く研究されている、人間にも当てはまる態度です。

AIにおいても同様のことが言われており、多くのAIは計算コストやレスポンスタイムの制約から、最適解を追い求める代わりに「十分に良い」回答と判断した時点で探索を打ち切る傾向があるとされています。
今回の調査においても、多くのモデルで途中打ち切りによる妥協回答が確認されたということですが、特に、o3モデルは上述の「長い思考」訓練によってサティスファイシングを抑制し、最適解に近い出力を追求できたため、ランキング1位に輝いたと考えられています。
また、DeepSeek-R1やMistral Smallのような無料・低価格モデルも、性能を急速に高めており、差が縮まっている傾向が見られます。
モデルのトレーニング方法も性能を向上させるうえで非常に重要な要素なんですね。
ということで、今回はAIの調査能力というトレンドの調査結果についてお伝えしました!
生成AIを使いこなす…
生成AIを使いこなすうえでは、個別具体的な状況と照らし合わせて、最適な活用方法を見出すことが大切です。
また、生成AIを「活用する」だけでは、多くの場合なんの成果も得られない状態に陥ってしまうことも事実。
副業で稼ぐなら、具体的にどうやってお金を稼ぐ手段を作るのか、顧客に購買してもらうためにどうすればいいのか、といった生成AI活用以外の知識も必要です。
ビジネスのDX化を推進するなら、業務の一部をデジタル化すればいい、というものではなく、業務フロー全体の見直しをして、デジタル化に最適な流れを作らなければなりません。
あなたの目指したいゴールに向かって必要なステップの全体を俯瞰して、抜本的な解決策を提案し、実践に導き同伴するサービスも行っています。
興味のある方は下記よりZoom個別相談へお越しください。
個別相談であなたの課題を洗い出していきましょう。
↓↓↓(画像をクリックすると、日程調整フォームに遷移します)

こはくのAIエージェントバイブル『ラフテル』も好評!